In this article on my blog I summarized my views on the proper way to obtain a robust solution through neroevolution.
Basically I question the whole architecture of the neuron when you are going to use genetic optimization or particle swarm optimization.
I suggest a different architecture, in this architecture we replace the transfer function by more complex mathematical representation and we evolve the weights inside. Doing so we are able to boost the power of the neural network.
The use of the logistic map as a very complex mathematical representation allow to add much more power to the neural net. By tuning the parameters (r) we can add a portion of chaos and by this improve the robustness.
This architecture is useful when no global solution exist and we face multiple local optima. In such case we want to find practical but robust solution.
What is the basic idea of this neuron architecture. The basic idea is that we are not looking for a global optimum at all. Why? Because we know that this global optimum does not exist.
I would refer to the Hitchiker's guide to universe:
"Narrator: There is a theory which states that if ever anyone discovers exactly what the Universe is for (I replace with the market) and why it is here, it will instantly disappear and be replaced by something even more bizarre and inexplicable. There is another theory which states that this has already happened."
So we know that we have multiple local optima, and no global optimum at all. In fact to find a local optimum is not a problem at all. What we are looking for is to find a stable solution. And that stable solution can be achieved only if you let the genetic optimizer evolve the weights into a complex mathematical space.
So let see what is all about.
The use of genetic algorithm for training SVM models is not something new. Let start from the standard artificial neuron model. However we are going to do something different. We are not going to map the inputs into a multidimensional space. We are going to put the agents into multidimensional space.
The first thing to do is to have a look a the basic structure of the artificial neuron model. I think the relevant Wikipedia article is a very good reference:
"For a given artificial neuron, let there be m + 1 inputs with signals x0 through xm and weights w0 through wm. Usually, the x0 input is assigned the value +1, which makes it a bias input withwk0 = bk. This leaves only m actual inputs to the neuron: from x1 to xm.

 (phi) is the transfer function.
(phi) is the transfer function.
The output is analogous to the axon of a biological neuron, and its value propagates to input of the next layer, through a synapse. It may also exit the system, possibly as part of an output vector.
It has no learning process as such. Its transfer function, weights are calculated and threshold value are predetermined."
So this is the basic neuron model and different learning methods can be applied.
A research paper was proposing a another possible structure making the traditional neuron model more complex."The basic idea is in representing the weights, that belong to interconnections in the neural network, by function. The learning process then doesn't happen directly on the level of weights like it is common in normal neural networks, but instead it happens by changing the function that is used to generate the weight every time when its value is needed."
The resulting neural network is called Hyper neural network. In the paper two approaches are used the representation of a function as a compressed matrix of coefficients used for Inverse Discrete Cosine transformation and representation of a function a a tree composed of elemental operations.
Another possibility is to make something different. We can vary the value of the weight using the formula of a transfer function and by this we may eliminate the use of a transfer function. We can vary and optimize the weight (using transfer function formula).
In the theoretically the biologically inspired neural networks, there the activation function is an abstraction it represents the rate of action potential firing in the cell. However we may not need this abstraction for some practical problems.
By doing this we diverge from the general neural model. The question is what we can gain from that? What are we going to do?
The simplest thing is to use simple transfer functions and vary them (here we will generate a population from the transfer function), then to multiply the result to the input and that is the output.
In the normal model in its simplest form you take the input you multiply by the weight then you input this result within the transfer function to get the response.
However here you can do something different. You can use complex representations and generate populations from them.
You can watch the video in this link to see a practical implementation of approximation of function by genetic algorithm using the Trading Software Metatrader 5. You can read more how the software works on this link.
Then the learning happens on the level of the transfer function. You may vary also the weights too but here we will not do so.

This is the Gaussian function. On the next picture you can see how the genetic algorithm approximate that.

From this the neuron model will look like this:
double perceptron()
{
double weight1 = MathExp(gamma*(-x1*x1-y1*y1));
double weight2 = MathExp(gamma*(-x2*x2-y2*y2));
double input1 = iCustom(TimeFrame,Symbol(),"PFE",x5,true,5,0,0);
double input2 = iCustom(TimeFrame,Symbol(),"PFE",x6,true,5,0,0);
double input3= iCustom(TimeFrame,Symbol(),"PFE",x7,true,5,0,0);
double input3= iCustom(TimeFrame,Symbol(),"PFE",x8,true,5,0,0);
return ( weight1* input1 + weight1* input2 + weight2*input3 + weight2* input4);
}
-We use the genetic algorithm to vary the values of the weights:
x1, x2,y1,y2
-You can modify at will the architecture
-This model is different from the classical neuron model. We do not have a transfer function. By doing this we eliminate the need of transfer function, you can add it but it is not necessary.
However we can use even more complex representations: We can use the logistic map as a complex space and vary the parameters of the logistic map.

That is the equation of the logistic map.
What is interesting for us is the parameter r. If we vary the parameter we will have different behaviour (sensitivity of the initial conditions). I keep it short here but we can get some very interesting stretching-and-folding structures.


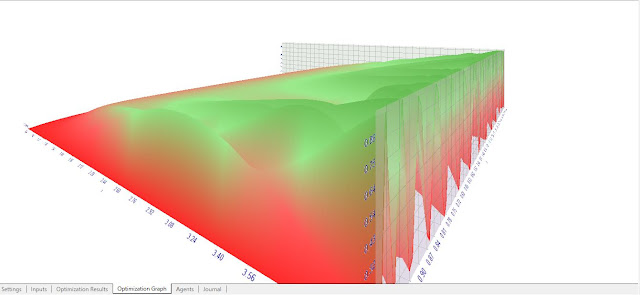
This is 3d picture of the logistic map. Logistic map as a kernel function. Why not?
We have a very complex representations from a very simple formula and the properties of the logistic map are well known.
Here we use:
- RECURRENT DIFFERENCE EQUATION: the code is simple however the recurrence is not supported by OpenCL by now.
- TO USE SOME PORTION OF CHAOS: this can be obtained by varying the value of r approximately 3.57 is the onset of chaos, so we can limit from 1 to 3, if we want to add some chaose we can go from 1 to 4 . The use of noise in the neural net training is a common pragmatic approach to increase the robustness of the solution. The x value os from 0.001 to 1 with step size of 0.001 for example. We can vary the number of iterations (limitmap) to as a parameter. As a result we get something terribly complex.
The idea here is that there is not a global optimum and we do not want to find it. It is counter - intuitive.
A sample code of this using the mql4 language (the language is based on C) is like this:
double weight1()
{
double w, j;
w=(r*x*(1-x));
for(j=0;j<=limitmap;j++)
{
w=(r*w*(1-w));
}
return (w);
}
double weight2()
{
double z, i;
z=(r1*x1*(1-x1));
for(i=0;i<=limitmap1;i++)
{
z=(r1*z*(1-z));
}
return (z);
}
double perceptron()
{
//---
{
double p1 = iCustom(NULL,0,"PFE",x5,true,5,0,0);// those are inputs
double p2 = iCustom(NULL,0,"PFE",x6,true,5,0,0);
double p3 = iCustom(NULL,0,"PFE",x7,true,5,0,0);
double p4 = iCustom(NULL,0,"PFE",x8,true,5,0,0);
}
return(weight1()* p1 + weight1()* p2 + weight2()*p3 + weight2()* p4);
}
Няма коментари:
Публикуване на коментар